Tutorial: Fine-Tuning a Model on Your Own Data
Last Updated: November 20, 2023
- Level: Intermediate
- Time to complete: 15 minutes
- Nodes Used:
FARMReader - Goal: After completing this tutorial, you will have learned how to fine-tune a pretrained Reader model on your own data.
Overview
For many use cases it is sufficient to just use one of the existing public models that were trained on SQuAD or other public QA datasets (e.g. Natural Questions). However, if you have domain-specific questions, fine-tuning your model on custom examples will very likely boost your performance. While this varies by domain, we saw that ~ 2000 examples can easily increase performance by +5-20%.
Preparing the Colab Environment
Installing Haystack
To start, let’s install the latest release of Haystack with pip:
%%bash
pip install --upgrade pip
pip install farm-haystack[colab,inference]
Enabling Telemetry
Knowing you’re using this tutorial helps us decide where to invest our efforts to build a better product but you can always opt out by commenting the following line. See Telemetry for more details.
from haystack.telemetry import tutorial_running
tutorial_running(2)
Create Training Data
There are two ways to generate training data:
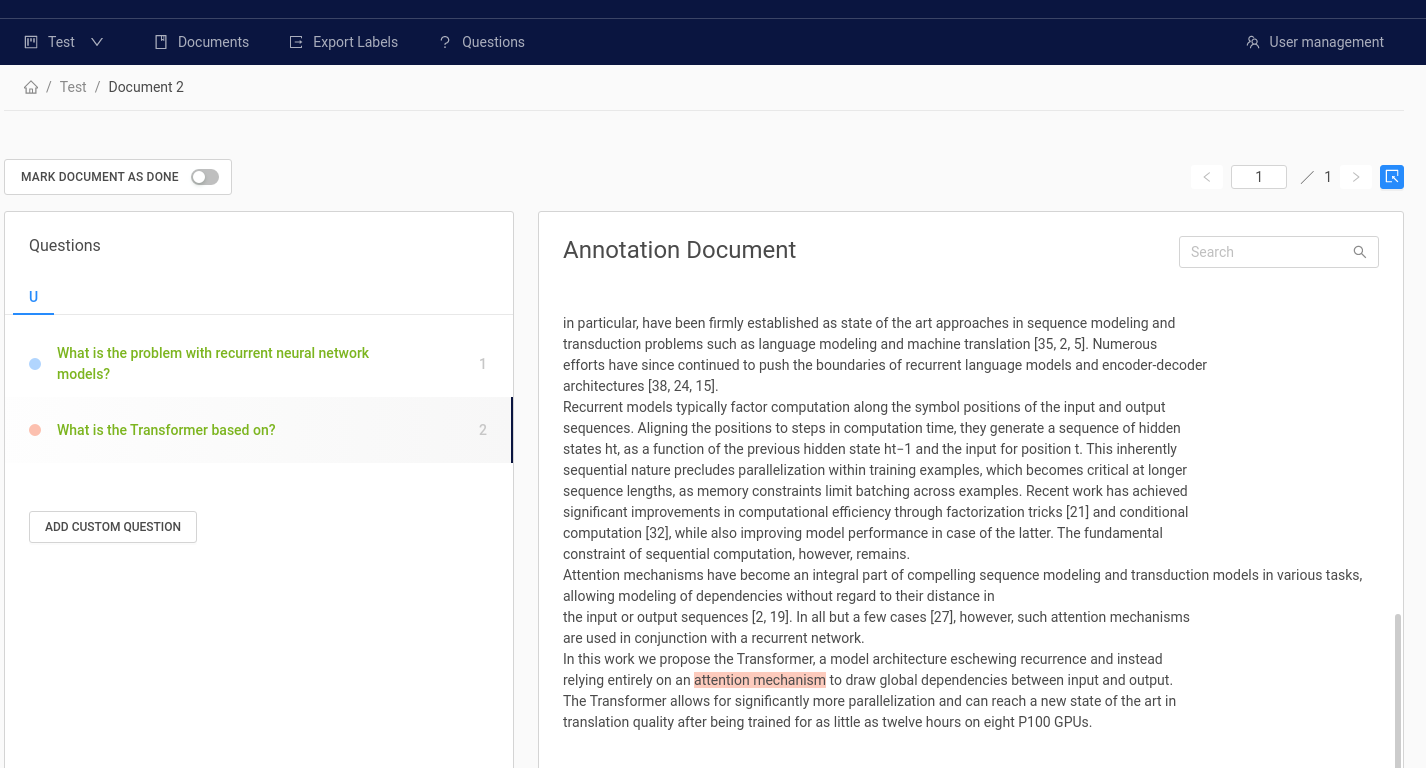
- Annotation: You can use the annotation tool to label your data, which means highlighting answers to your questions in a document. The tool supports structuring your workflow with organizations, projects, and users. The labels can be exported in SQuAD format that is compatible for training with Haystack.
- Feedback: For production systems, you can collect training data from direct user feedback via Haystack’s REST API interface. This includes a customizable user feedback API for providing feedback on the answer returned by the API. The API provides a feedback export endpoint to obtain the feedback data for fine-tuning your model further.
Fine-Tune Your Model
Once you have collected training data, you can fine-tune your base model. To do that, you need to initialize a reader as a base model and fine-tune it on your custom dataset (should be in SQuAD-like format). We recommend using a base model that was trained on SQuAD or a similar QA dataset beforehand to benefit from Transfer Learning effects.
Recommendation: Run training on a GPU.
If you are using Colab: Enable this in the menu “Runtime” > “Change Runtime type” > Select “GPU” in dropdown.
Then change the use_gpu arguments below to True
- Initialize a
Readerwith the model to fine-tune:
from haystack.nodes import FARMReader
reader = FARMReader(model_name_or_path="distilbert-base-uncased-distilled-squad", use_gpu=True)
- Get SQUAD-style data for training. You can use this dataset we prepared:
from haystack.utils import fetch_archive_from_http
data_dir = "data/fine-tuning"
fetch_archive_from_http(
url="https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-downstream/squad20.tar.gz", output_dir=data_dir
)
- Train the model on your own data and save it to “my_model”
reader.train(data_dir=data_dir, train_filename="squad20/dev-v2.0.json", use_gpu=True, n_epochs=1, save_dir="my_model")
- Initialize a new reader with your fine-tuned model:
new_reader = FARMReader(model_name_or_path="my_model")
- Finally, use the
new_readerthat was initialized with your fine-tuned model.
from haystack.schema import Document
new_reader.predict(
query="What is the capital of Germany?", documents=[Document(content="The capital of Germany is Berlin")]
)
Congratulations! 🎉 You’ve fine-tuned a base model on your own data!